
За последний год многие попробовали ИИ. С помощью одного запроса можно составить контракт, другого — написать ответ на письмо, третьего — разобраться в сложной таблице. Так что можно сказать, что многие уже «использовали ИИ в бизнесе». Однако одно дело использовать подсказки ИИ для разовой задачи, и совсем другое — вписать ИИ в бизнес-процесс. Так, чтобы он день за днём работал и приносил результат без сиюминутного контроля. В этом и состоит разница между «я попробовал ChatGPT» и «ИИ работает на мой бизнес», и вторым пока могут похвастаться немногие. Собственно именно об этом речь в статье. Использование ИИ в бизнес-процессах — это не автоматизация «на стероидах», а способ быстрой адаптации бизнеса под изменения на рынке, открывающий куда большие перспективы.
Оглавление
- Бизнес-модель
- Надо бежать чтобы оставаться на месте
- ИИ в бизнес-процессах: автоматизация, оптимизация, обнаружение отклонений
- КПД процесса: процент успешного первого прохождения
- Как это выглядит на практике
- С чего начинать: данные, а не ERP
- Шанс на успех и подводные камни
- Часто задаваемые вопросы
Бизнес-модель
Если вырваться из операционки и взглянуть на бизнес в целом — на то, как на самом деле работает ваша компания, — то понятно, что вы не управляете каждой транзакцией вручную: у вас для этого есть система из людей, процессов, систем и данных, которую обычно называют модель бизнеса. Модель — это абстракция живого организма бизнеса, она отбрасывает несущественное, сохраняя главное — возможность управления. Это стандартная схема People–Process–Technology, которая существует десятилетиями; но в последнее время туда добавляют данные как четвёртый самостоятельный элемент, объединяющий остальные три.
Управление бизнесом на основе моделей — устоявшаяся практика, и каждая новая волна технологий давала менеджерам новые инструменты: организационные структуры, стандартные операционные процедуры, ERP, дашборды. Системы ИИ — новейшее из этих средств, и использование ИИ в бизнес-процессах — это один из элементов более широкой ИИ-трансформации бизнеса.
В начале карьеры, будучи бизнес-аналитиком, я для описания бизнес-модели рисовал процессные диаграммы: карты процессов IDEF0, матрицы CRUD, спецификации use-case — формальное описание того, как должен протекать рабочий процесс. И я видел, как эти диаграммы устаревали почти сразу после завершения работы над ними, потому что бизнес, который они описывали, менялся и двигался вперёд. Системы становились всё сложнее, эволюционируя в ERP и всё жёстче диктуя свои «процессы», а «людям» доставалось всё больше исключений, с которыми эти системы не справлялись. Предприятия вкладывали огромные деньги в ERP, которые на бумаге сулили экономию, прозрачность и управляемость бизнеса, а по факту оказывались бездонной бочкой для инвестиций и требовали ещё больше людей на ведение бизнеса. В отличие от систем прошлого поколения ИИ напрямую затрагивает еще и слой людей: ИИ-системы можно обучить обрабатывать ситуации, которые раньше требовали вмешательства человека.
Надо бежать чтобы оставаться на месте
Распространено мнение, почему операционные модели оказываются не слишком эффективны для управления бизнесом: считается, что они не охватывают достаточно вариаций — «мы знаем основной сценарий, но не подумали об этом исключении из правил». Это верно, но лишь отчасти: описание всех вариаций процесса — большая и бесполезная работа. Аналитики всегда моделировали вариации. IDEF0, диаграммы use-case, BPMN — эти обозначения существуют именно для того, чтобы фиксировать ветви, исключения и альтернативные пути.

Проблема не в том, что бизнес-аналитики не удосужились тщательно описать все вариации. Проблем две, и они не в усидчивости аналитиков. Первая: при усложнении модели она буквально взрывается. Каждое добавление исключения множит ветви, пока диаграмма не превращается в запутанный клубок размером со стену, в котором уже никто не может разобраться и который невозможно поддерживать. Вторая, и самая важная: модель точна только в момент её создания. Бизнес — живое существо в постоянно меняющемся рынке. На следующий день после того, как вы завершите карту процессов, поставщик изменит условия, конкурент скорректирует цены, выйдет новый закон, клиент поведёт себя так, как ваша карта не предусмотрела. Модель и реальность начинают расходиться друг с другом. Разрыв незаметно растёт, и по мере его увеличения вы теряете две вещи: эффективность (работа идёт в обход официального процесса) и контроль (вы больше не знаете, как на самом деле работает бизнес).
Создание более крупной и детализированной статической модели не решает проблему — она добавляет как нечитаемость, так и более быстрое устаревание. Это вечная управленческая проблема — то, как мы представляем себе бизнес, и как он функционирует на самом деле. Настоящая инновация Agile заключалась не в странных ритуалах, а в сокращении временного шага: меньшие инкременты, более быстрая обратная связь, меньше дрейфа между исправлениями. Более короткие интервалы планирования требуют меньшего управленческого опыта и быстрее позволяют исправить как допущенные ошибки, так и постоянный дрейф рынка. Отсюда возникает очевидный вопрос: как ещё сильнее сократить цикл принятия решений?
ИИ в бизнес-процессах: автоматизация, оптимизация, отслеживание отклонений
Ответ не в «более крупной и умной модели, которая наконец охватит всё». Это старая ловушка, в которую легко попасться, обладая всё более крупными вычислительными мощностями. Ответ в том, чтобы намеренно сохранять модель простой и позволить ИИ отслеживать границу — непрерывно сравнивать то, что происходит на самом деле, с тем, что должно происходить по модели, и отмечать, где они расходятся. Адаптация становится рутинной и недорогой деятельностью, а не периодической и дорогостоящей перестройкой. У этого процесса есть устоявшееся название: process mining (анализ процессов) или проверка соответствия — сравнение реальных логов с нормативной моделью для выявления отклонений. ИИ не привнес это понятие, он просто позволяет это делать проще и чаще.
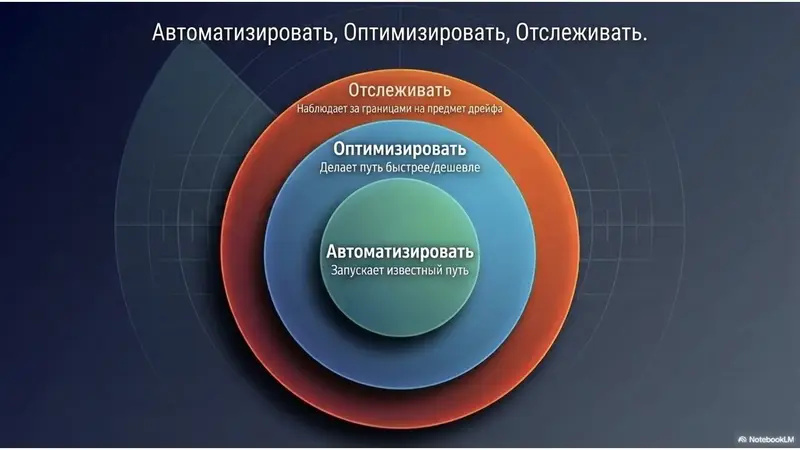
Мы считаем, что ИИ может делать три полезные вещи, погружаясь в бизнес-процесс:
- Автоматизировать — выполнить основной путь процесса. Это базовый уровень, который предлагают все, и автоматы RBA (автоматизация на основе правил) умеют это делать уже давно.
- Оптимизировать — сделать известный путь быстрее, дешевле или точнее, устранить лишние вариации. Тоже уже неплохо изученная область.
- Отслеживать — замечать, когда реальность перестала соответствовать процессу. Это новое и ключевое, потому что именно отслеживание делает адаптацию возможной.
Именно эта третья способность позволяет ИИ быть на голову выше предыдущих систем. Классический механизм на основе правил предполагает заданный путь; в тот момент, когда появляется что-то, что не предусмотрено правилами, механизм либо выдаёт ошибку, либо молча делает что-то не то. ИИ способен обрабатывать неструктурированные, заранее неизвестные сигналы дрейфа, которые фиксированный механизм правил не способен распознать: ряд запросов на возврат средств, сформулированных пятью разными способами; счёт-фактура, не совпадающая ни с одним шаблоном; паттерн в очереди поддержки, который никто не отметил. Механизм на основе правил отрабатывает заданный процесс. ИИ замечает, когда процесс перестал соответствовать реальности.
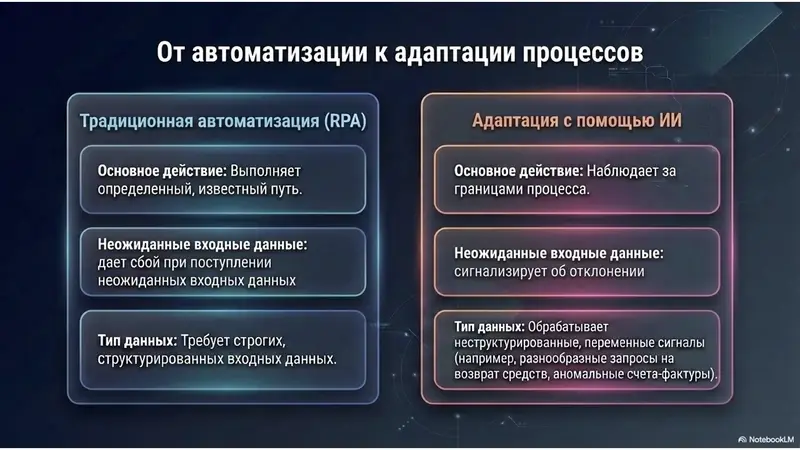
Поясню на примере. Возьмем дебиторскую задолженность. Автоматизация сопоставляет входящие платежи с открытыми счетами и обрабатывает известные варианты. Обнаружение отклонений — это другая логика: ИИ замечает, что конкретный клиент незаметно перешёл от оплаты за 10 дней к оплате за 30, что группа счетов не распознается из-за изменения поля у контрагента, что растёт категория нераспознанных платежей. Ни один из этих случаев не является вариантом, для которого есть правила. Это дрейф — и именно такой сигнал фиксированная автоматизация просто пропустит.
Необходимо отметить: анализ процессов корпоративного уровня предполагает наличие чистого, структурированного журнала событий, которого у большинства небольших компаний просто нет. Поэтому версия для малого и среднего бизнеса — не готовый набор для проверки соответствия; это намеренно простая модель плюс ИИ, который следит за несколькими важными процессами. Именно поэтому слой данных является реальным предварительным условием для ИИ-трансформации, а не проект внедрения ERP. Мы подробнее рассмотрим этот вопрос в отдельной статье.
КПД процесса: процент успешного первого прохождения
Для оценки того, насколько эффективно работает процесс, есть хорошая метрика: процент успешного первого прохождения (first-pass rate), также известный как сквозная обработка (straight-through processing) — доля счетов, заказов (или любых других входных артефактов), которая проходит процесс от начала до конца по основному пути, без вмешательства человека. Для обработки счетов, приёма заказов или ввода клиента в работу ведущие компании достигают 80 % и выше. Эта метрика не обрисовывает всю картину, но она чётко показывает, насколько хорошо ваша модель всё ещё соответствует реальности. Когда процент успешного первого прохождения падает, больше работы выпадает из автоматизированного пути в ручную обработку. Это и есть сигнал дрейфа — и его вполне можно уловить.
Важное различие. ИИ повышает процент успешного первого прохождения не за счёт замены вашего набора правил и не за счёт поглощения всех возможных вариаций — это снова будет ловушкой статической модели. Он повышает его за счёт обнаружения отклонений, которые устаревшая модель молча пропустила бы, и перенаправления их на обработку или включение в модель. Число растёт, потому что меньше работы незаметно проваливается сквозь трещины, а не потому, что машина теперь притворяется, что справляется со всем.
Как это выглядит на практике
Два примера из нашей собственной практики.
Первый пример — Royal Finance, брокер по кредитам, чей гибридный чат-бот снизил нагрузку на операторов на 60–70 %. Здесь важно не процент автоматизации, а разделение. Детерминированные правила управляют выбором продукта на регулируемом рынке, где цена ошибки высока (квалификация продукта, сопоставление, ставки берутся прямо из базы данных), и в промышленной эксплуатации по этим правилам обрабатывается 85 % входных заявок без участия языковой модели. ИИ-агенты берут на себя только сложные остатки: свободный текст, когда клиент пишет «три миллиона» вместо того, чтобы нажать кнопку, или задаёт вопрос, которого нет в правилах. Это миниатюрный цикл проверки соответствия. Детерминированная модель владеет фиксированным путём; ИИ следит за границей и обрабатывает отклонения, а там, где ИИ не справляется, он перенаправляет, а не угадывает, потому что неправильный ответ о процентной ставке или сумме кредита — неприемлемая ошибка. Подробнее о том, когда создавать собственного ИИ-чат-бота, а когда покупать платформу
Второй пример: ИИ-агент, который создаёт большую часть нашего SEO-контента. Каждый черновик, который он пишет, проходит через строй автоматизированных критиков, которые оценивают контент по фиксированной планке качества; черновики, которые не соответствуют этой планке, отмечаются и отправляются на доработку. Этот фильтр критиков и есть цикл проверки соответствия: нормативная модель (планка качества) непрерывно сверяется с фактическим результатом (каждым черновиком), а отклонения выявляются, а не уходят в работу.
Стоит отметить, что написание контента — это генеративная задача; её результат недетерминирован в отличие от сопоставления счёта с платежом. Нельзя запустить генеративный процесс без присмотра так же, как детерминированный. Фильтр критиков установлен именно поэтому — это слой отслеживания, который выявляет дрейф, а затем человек решает, что с этим делать. Мы не считаем, что ИИ-агенты должны быть полностью автономными: обнаружение отклонений и обработка их человеком делают недетерминированный ИИ безопасным для реального рабочего процесса.
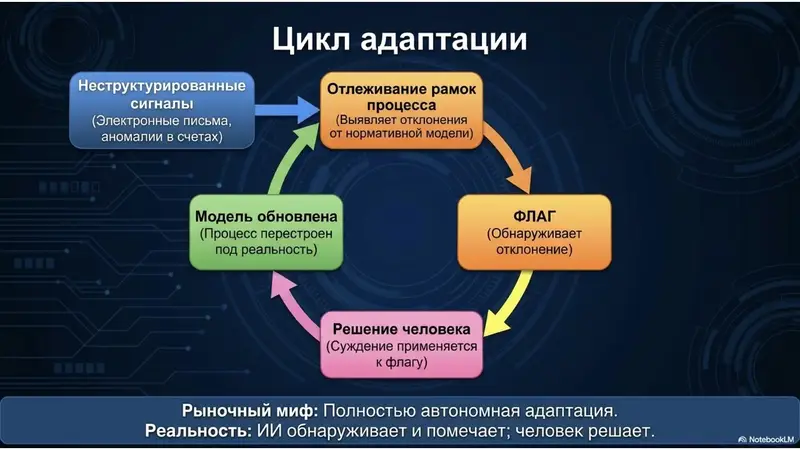
Это осознанное включение человека в рабочий цикл, о котором все обычно умалчивают. Вы услышите слова «замкнутый цикл» и «автономная система», как будто система сама обнаруживает дрейф и решает, что с этим делать. Мы намеренно проектируем иначе: ИИ обнаруживает, человек решает. Это не урезанная версия автономности — это версия, которая применима в реальном бизнесе, и она оставляет принятие решений там, где оно и должно быть. (Есть и второй, отдельный «дрейф», о котором рынок любит говорить: ухудшение модели ИИ со временем. Это реальная проблема, но она отличается от той, о которой говорится в этой статье. Подробнее об этом различии в следующей статье.)
С чего начинать: данные, а не ERP
Если перед вами встал вопрос, с чего начать ИИ-трансформацию, большинство консультантов ответит одинаково: сначала цифровизация, потом ИИ. И под цифровизацией вам предложат внедрить ERP или что-то похожее. Да, действительно, отслеживание бизнес-процессов будет работать, только если ИИ погружён в ваш бизнес и чётко видит его, а для этого нужен непротиворечивый, структурированный слой данных. Однако все же это не причина заводить прожорливого монстра в своем огороде.
Вам не нужно доводить до победного конца цифровую трансформацию или устанавливать масштабную ERP, прежде чем приступать к работе с ИИ. Часто предлагается сначала многолетняя перестройка систем, потом, возможно, ИИ. И для среднего бизнеса такая последовательность — ловушка, которая фактически гарантирует, что ИИ так и не появится. Что вам действительно нужно — Data foundation (фундамент данных), а не хранилище данных: достаточно чистых, связанных данных об одном или двух рутинных проблемных процессах, чтобы у ИИ было что отслеживать. Начните с этого. Один массовый, рутинный, проблемный процесс, достаточно хороших данных, чтобы им управлять, и такое внедрение быстро окупится, при этом не затрагивая остальную часть компании. Это также вписывается в более широкую стратегию работы с ИИ: процессы — лишь один слой, а не всё её содержание.
ИИ действительно помогает вам интегрировать фрагментированные данные — извлекать данные из CRM, бухгалтерской системы, разрозненных электронных таблиц и почтового ящика, которые никогда не были предназначены для взаимодействия друг с другом. Но он не избавляет от необходимости хранить эти данные структурированными, согласованными и управляемыми. Принцип «мусор на входе — мусор на выходе» никто не отменял. ИИ избавляет от тяжёлого труда по обработке данных, но не отменяет наведение порядка в них. Направьте ИИ на неуправляемый хаос, и вы получите не понимание, а хаос в квадрате. Это не просто замечание; это самая распространённая причина, по которой пилотные проекты терпят неудачу. Цифры это подтверждают: в одном опросе 2026 года 61 % руководителей по работе с данными заявили, что повышение качества данных — это то, что действительно переводит ИИ из пилотного проекта в промышленную эксплуатацию, а организации со зрелой системой управления данными сообщили о примерно 24 % более высоком доходе, связанном с ИИ.
Шанс на успех и подводные камни
Краткий список того, как это может пойти не так, исходя из приведённых выше аргументов:
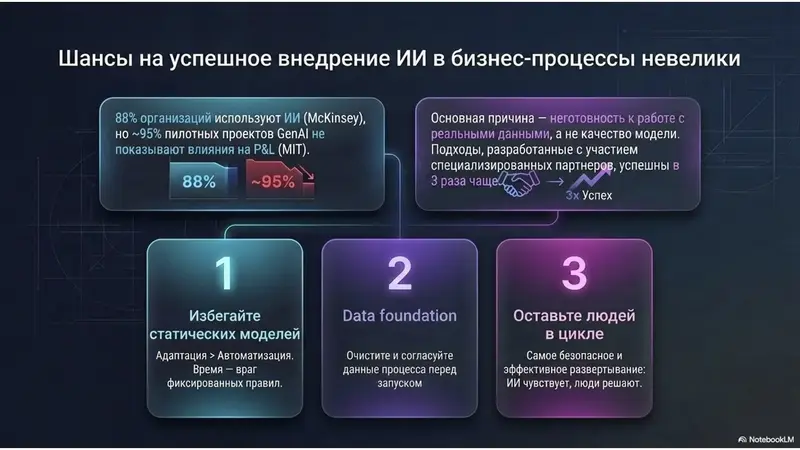
- Не старайтесь построить совершенную модель бизнес-процессов. Несмотря на то что ИИ-инструменты теперь позволяют упростить создание процессных моделей, то, что не работало раньше, не будет работать и сейчас — и вы заплатите за это на этапе внедрения систем под эту бизнес-модель.
- Не гонитесь за автономностью. Обнаружение отклонений — задача ИИ; принятие решений — ваша. Система, которую продают как полностью автономную, либо преувеличивает свои возможности, либо перекладывает на вас риски, не афишируя это.
- Не запускайте ИИ на несогласованных данных. Без Data foundation (фундамента данных) ИИ будет теряться в догадках и путаться в элементарных вещах.
- Начинайте с простого и короткого цикла. Простая модель, которую ИИ поддерживает в актуальном состоянии, лучше идеальной модели, которая уже устарела.
И, к сожалению, если смотреть на статистику, то ваши шансы на успех невелики. Цифры, которые часто цитируются (и используются как страшилки) — они реальны, но они указывают именно на сложность погружения ИИ в бизнес, а не бесперспективность ИИ-систем. Исследование McKinsey 2025 года State of AI показало, что 88 % организаций уже используют ИИ хотя бы в одной функции, но лишь небольшая доля получает ощутимую финансовую отдачу. Исследование MIT GenAI Divide дало более резкие цифры: примерно 95 % пилотных проектов с генеративным ИИ не дали ощутимого влияния на P&L. Но обратите внимание на первопричину, потому что в этом и есть суть — неудачи связаны с пробелом в знаниях, с работой по интеграции ИИ в реальный рабочий процесс, структуру и культуру, а не с качеством самих моделей. Те же исследования показали, что подходы, разработанные с помощью специализированных партнёров, удавались примерно в три раза чаще, чем внутренние попытки «сделай сам». Этот разрыв между «мы попробовали ChatGPT» и «мы погрузили ИИ-агента в бизнес-процесс» — именно то, с чего мы начали эту статью, и его можно преодолеть осознанно, а не методом проб и ошибок.
Если вам нужен взгляд со стороны, чтобы определить, какой из ваших процессов дрейфует сильнее всего и готовы ли ваши данные к тому, чтобы ИИ мог их отслеживать, именно с этого начинается ИИ-консалтинг. Мы выявляем дрейф, прежде чем кто-либо напишет хоть строку автоматизации.
В следующих статьях мы подробнее рассмотрим те аспекты, которые в этом обзоре только затронули: как измерять соответствие между моделью и реальностью без корпоративных инструментов, как механизм обнаружения дрейфа реально работает для бизнеса вашего размера и что означает корпоративная волна «автономности» для компании, которая не является корпоративной.
Часто задаваемые вопросы
Нужно ли мне ERP или завершённая цифровая трансформация, прежде чем начинать работать с ИИ? Нет. Вам нужно Data foundation (фундамент данных), а не хранилище данных — достаточно чистых, связанных данных об одном или двух процессах, которые действительно доставляют проблемы, чтобы у ИИ было что отслеживать. Совет завершить масштабную перестройку систем сначала — для большинства средних компаний способ гарантировать, что ИИ так и не будет запущен. Начните с одного проблемного процесса и достаточно хороших данных, чтобы чётко его увидеть.
В чём разница между автоматизацией процесса и его адаптацией? Автоматизация отрабатывает основной путь процесса — заданные входные данные, заданные шаги, определённый выход процесса, только быстрее и дешевле. Адаптация поддерживает соответствие этого пути реальности по мере её изменения: ИИ отслеживает, где реальные действия отклоняются от определённого процесса, и отмечает это, чтобы вы могли непрерывно корректировать модель, а не вдруг обнаружить, что модель больше не описывает ваш бизнес. Автоматизация — базовый уровень; адаптация — более сложная и ценная задача, и ИИ — новый доступный инструмент для неё.
Чем это отличается от RPA (автоматизации на основе правил)? Механизм автомата выполняет определённый путь и дает сбой, либо молча пропускает ситуацию, когда появляется что-то, что правила не предусмотрели. ИИ добавляет способность обрабатывать неструктурированные, переменные сигналы: он замечает исключения и дрейф, которые фиксированный набор правил не может уловить, и выявляет их. RPA отрабатывает процесс; ИИ замечает, когда процесс перестаёт соответствовать действительности.
ИИ сам решает, что делать с найденными проблемами? Нет — и это намеренно. ИИ обнаруживает дрейф и отмечает его; человек решает, что означает каждая выявленная ситуация и как реагировать. «Полностью автономная, замкнутая» адаптация — это в основном продающий маркетинг; для реальной работы в бизнесе системе надо продолжать учиться на основе человеческого суждения. Обнаружение плюс человеческое решение — вот что делает недетерминированный ИИ безопасным для реального рабочего процесса, и это разница между использованием ИИ в бизнес-процессах и простой попыткой его попробовать.


